System Initialization
Recommends having the constructor/deconstructor do nothing
so we can explicitly set the order of initialization via init
functions
gMemoryManager.startUp()
gFileSystemManager.startUp()
gVideoManager.startUp()
...
This is assuming most of the inizializations are for singletons
such as managers like TextureManager, RenderManager, etc.
- Naughty Dog Uncharted/Last of Us uses many statically allocated
singletons and a master init function called BigInit():
Memory Optimization
Keep heap allocations to a minimum, and never allocate from the
heap within a tight loop.
- Using new/malloc dynamic memory can be slow due to context switching between
user and kernel mode; need to go through OS
- Can optimize by writing your own custom allocator/manager
- Works be acting on a fixed global block of static memory
- Some common custom allocators are next
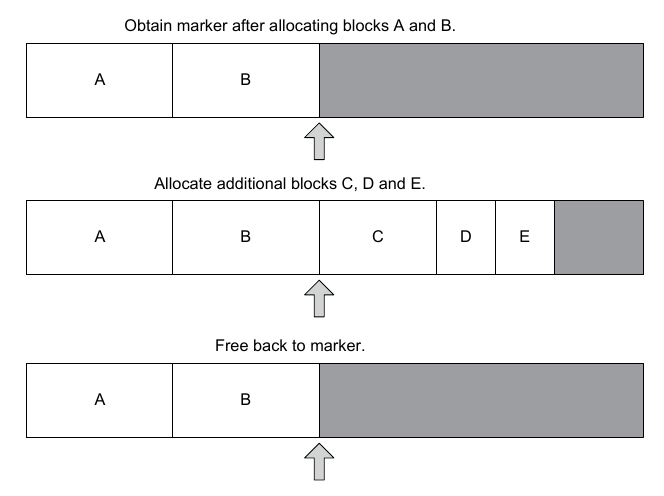
Stack Allocator
- Uses contiguous memory, assigning allocations in a stack form
(the next assigned memory is located at the stack pointer)
- Memory has to be de-allocated in reverse order
- Double ended stack allocator can allocate from both the bottom
and the top, eventually with the two stack pointers meeting
in the middle if you run out of memory
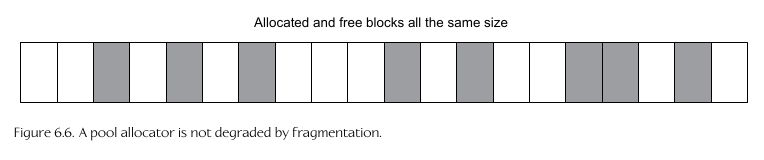
Pool Allocator
- Has a 'pool' of fixed-size memory regions (each block of memory is
exactly the same size)
- Useful if allocating a bunch of the same type
Aligned Allocation
inline uintptr_t AlignAddress(uintptr_t addr, size_t align)
{
const size_t mask = align - 1;
assert((align & mask) == 0);
return (addr + mask) & ~mask;
}
- Work by allocating a bit more memory than requested, then shifting
the result area increased by the alignment difference (by the alignment
value if the difference is zero, so we ALWAYS shift)
- the ~mask works like so: if alignment is 2 bytes, addresses must end
in 0x0 or 0x2:
- mask = 2-1 = 1 = 0b00000001, ~mask = 0b11111110
- input addr = 0b11101011 (odd address, not even)
- add + mask = 0b11101011 + 0b00000001 = 0b11101100
- res & ~mask = 0b11101100 & 0b11111110
- Store the amount shifted in the space to the left of the shifted area,
then the original, unshifted address can be calculated using that
shifted_amount = aligned_addr[-1]
Iterators
Its a good idea to override the increment/decrement operator for custom
containers like a home-written binary tree; the complexity of iterating
through the structure in usage is simplified to a ++/--
STL template library/container objects
- Can be slower or use more memory than a hand written object
designed for a particular problem
- Some other library options:
Strings and resource identifiers
- String operations can be slow and take up more space than integer
UIDs
- Idea is to hash string names of resources (e.g. C:\my\3d\model.obj) into
unique identifiers which can be referenced throughout the code in order to
avoid dealing with strings
At Naughty Dog, we permit runtime hashing of
strings, but we also use C++11’s user-defined literals feature to transform the
syntax "any_string"_sid directly into a hashed integer value at compile
time
At Naughty Dog, we started out using a variant of
the CRC-32 algorithm to hash our strings, and we encountered only a handful
of collisions during many years of development on Uncharted and The Last of
Us. And when a collision did occur, fixing it was a simple matter of slightly
altering one of the strings (e.g., append a “2” or a “b” to one of the strings,
or use a totally different but synonymous string). That being said, Naughty
Dog has moved to a 64-bit hashing function for The Last of Us Part II and all of
our future game titles; this should essentially eliminate the possibility of hash
collisions
i++ vs ++i
The postincrement operator increments the contents of the
variable after it has been used. This means that writing ++p introduces a data
dependency into your code—the CPU must wait for the increment operation
to be completed before its value can be used in the expression. On a deeply
pipelined CPU, this introduces a stall. On the other hand, with p++ there is no
data dependency. The value of the variable can be used immediately, and the
increment operation can happen later or in parallel with its use. Either way,
no stall is introduced into the pipeline. ... This shouldnt matter in loops
anyways due to compiler optimization
Dynamic Arrays
Dynamic arrays are
probably best used during development, when you are as yet unsure of the
buffer sizes you’ll require. They can always be converted into fixed size arrays
once suitable memory budgets have been established.
Development Memory
a PS3 development kit has 256 MiB of retail memory, plus
an additional 256 MiB of “debug” memory that is not available on a retail unit.
If we store our strings in debug memory, we needn’t worry about their impact
on the memory footprint of the final shipping game. (We just need to be careful
never to write production code that depends on the strings being available!)
Unicode (Important for localization/translation)
http://www.joelonsoftware.com/articles/Unicode.html
Localization Management
You will need to
manage a database of all human-readable strings in your game, so that they
can all be reliably translated. The software must display the proper language
given the user’s installation settings. The formatting of the strings may be to-
tally different in different languages—for example, Chinese is sometimes writ-
ten vertically, and Hebrew reads right-to-left. The lengths of the strings will
vary greatly from language to language
At Naughty Dog, we use a localization database that we developed in-house.
The localization tool’s back end consists of a MySQL database located on a
server that is accessible both to the developers within Naughty Dog and also
to the various external companies with which we work to translate our text
and speech audio clips into the various languages our games support
Game Configuration Examples
- Quake Engine family uses
cvar_t (configration variable) data type
which are accessible via the in-game console and can be saved to disk
- OGRE Render Engine uses *.cfg files
Naughty Dog Uncharted & Last of Us uses C++ code generated from scheme
programming language data definitions:
(deftype simple-animation()
(
(name string)
(speed float :default 1.0)
(fade-in-seconds float :default 0.25)
)
)
results in the generated C++:
struct SimpleAnimation
{
const char* m_name;
float m_speed;
float m_fadeInSeconds;
};